哲学与向量嵌入、OpenAI 和 Astra DB
AstraPy 版本
在本快速入门教程中,您将学习如何使用 OpenAI 的向量嵌入和 DataStax Astra DB 作为数据持久化的向量存储来构建一个“哲学名言查找器与生成器”。
本笔记本的基本工作流程概述如下。您将评估并存储许多名言的向量嵌入,利用它们构建一个强大的搜索引擎,然后甚至可以生成新的名言!
本笔记本例举了一些向量搜索的标准用法模式——同时展示了开始使用 Astra DB 是多么容易。
有关使用向量搜索和文本嵌入构建问答系统的背景知识,请参阅这篇出色的实践笔记本:使用嵌入进行问答。
目录:
- 设置
- 创建向量集合
- 连接到 OpenAI
- 将名言加载到向量存储中
- 用例 1:名言搜索引擎
- 用例 2:名言生成器
- 清理
工作原理
索引
每条名言都通过 OpenAI 的 Embedding 转换为嵌入向量。这些向量将与元数据一起存储在向量存储中,以便稍后用于搜索。一些元数据,包括作者姓名和其他一些预先计算的标签,会一起存储,以允许进行搜索定制。
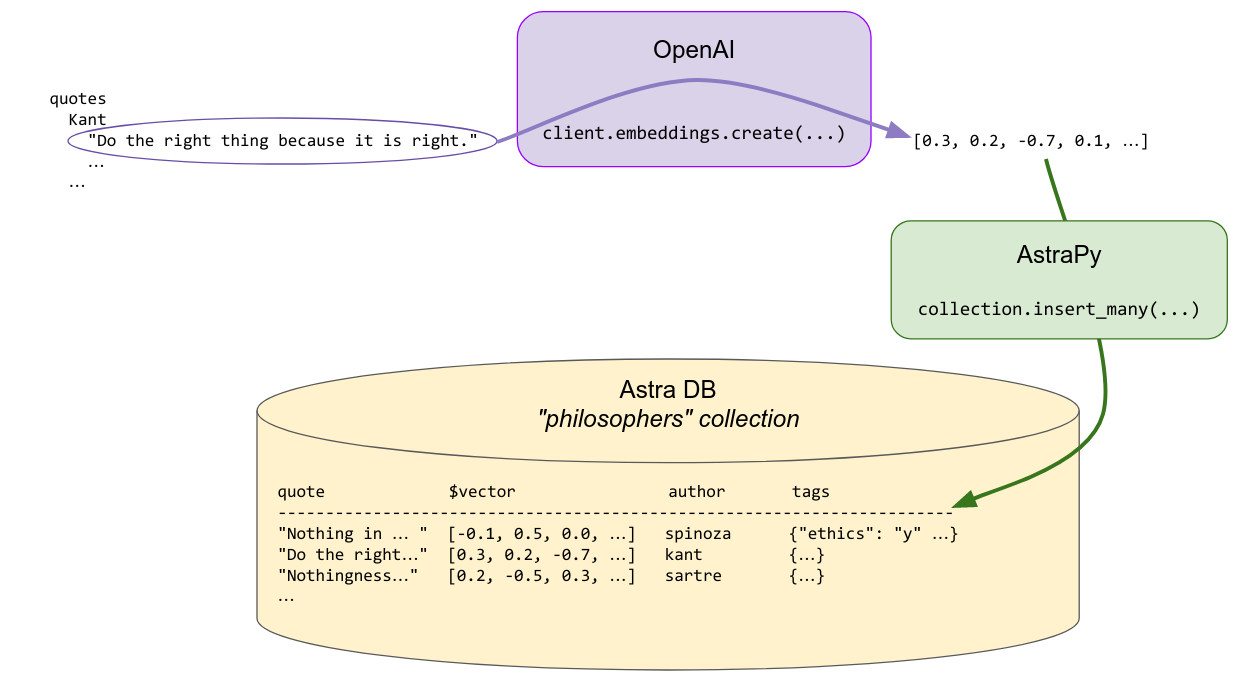
搜索
要查找与提供的搜索名言相似的名言,后者会即时转换为嵌入向量,然后使用该向量查询存储以查找相似向量……即之前索引的相似名言。搜索可以选择性地受其他元数据约束(“找到与此相似的斯宾诺莎的名言……”)。
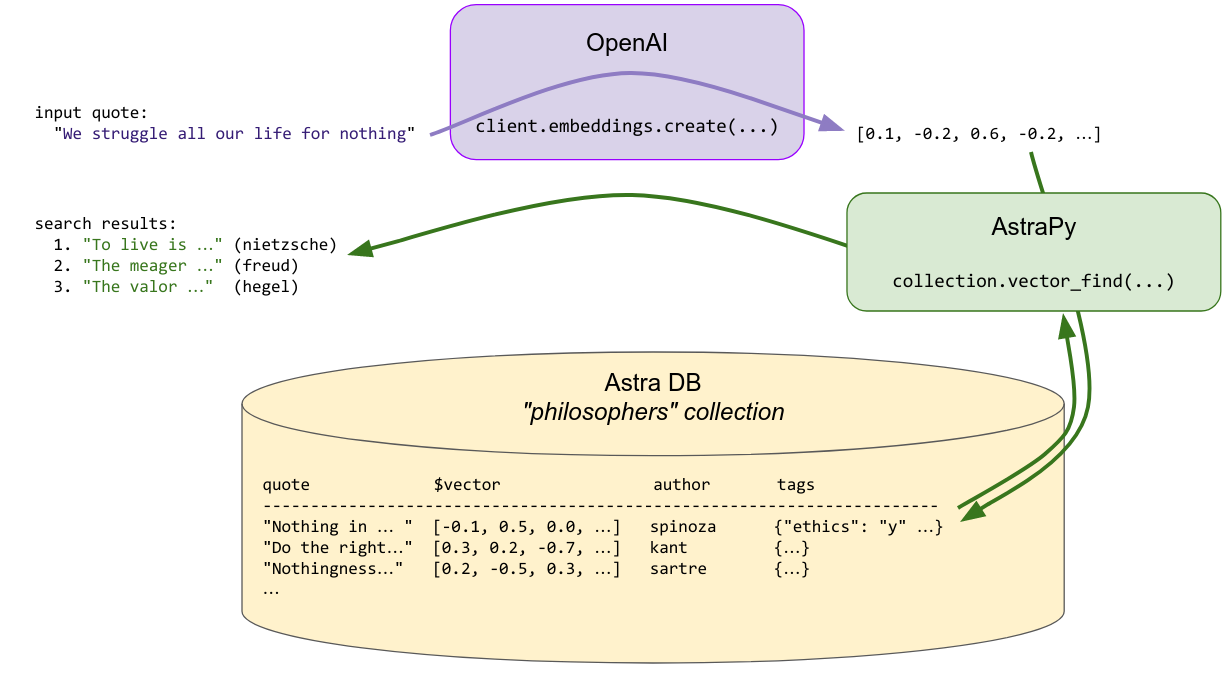
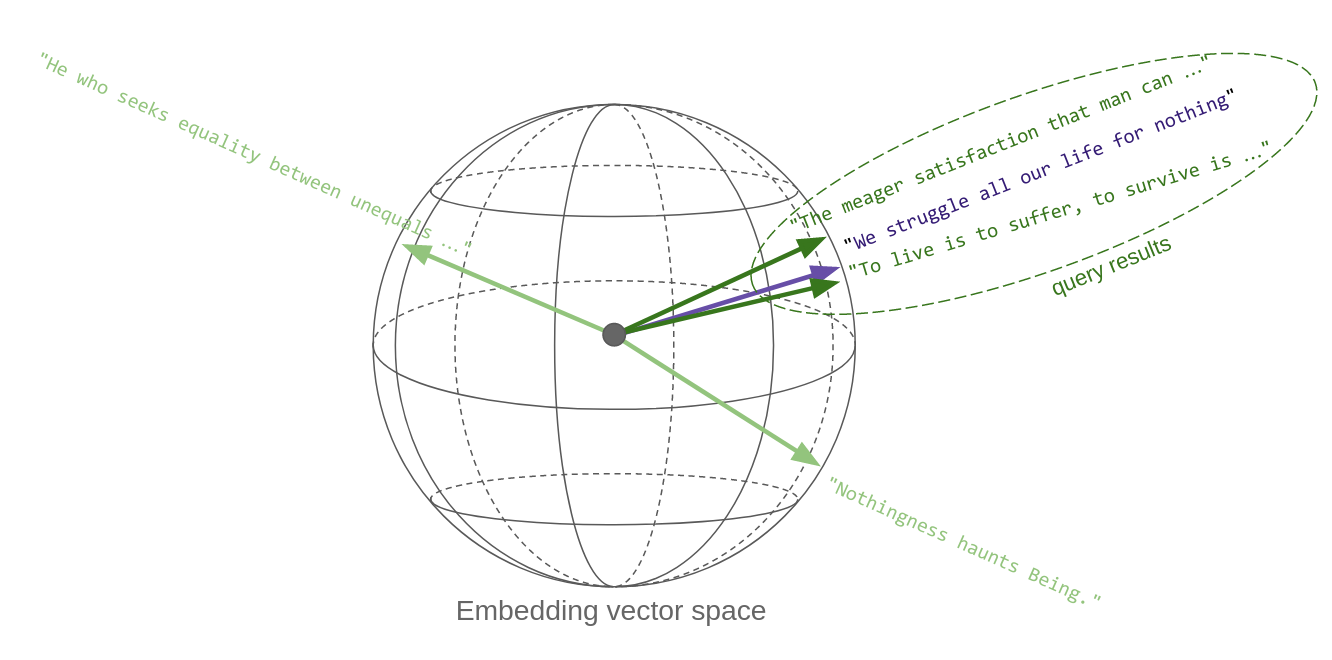
这里的关键点是,“内容相似的名言”在向量空间中转化为彼此在度量上接近的向量:因此,向量相似性搜索有效地实现了语义相似性。这是向量嵌入如此强大的关键原因。
下面的草图试图传达这个想法。每条名言一旦被转换为向量,就成为空间中的一个点。嗯,在这种情况下,它在一个球体上,因为 OpenAI 的嵌入向量,像大多数其他向量一样,被归一化为_单位长度_。哦,而且这个球体实际上不是三维的,而是 1536 维的!
所以,本质上,向量空间中的相似性搜索会返回最接近查询向量的向量:
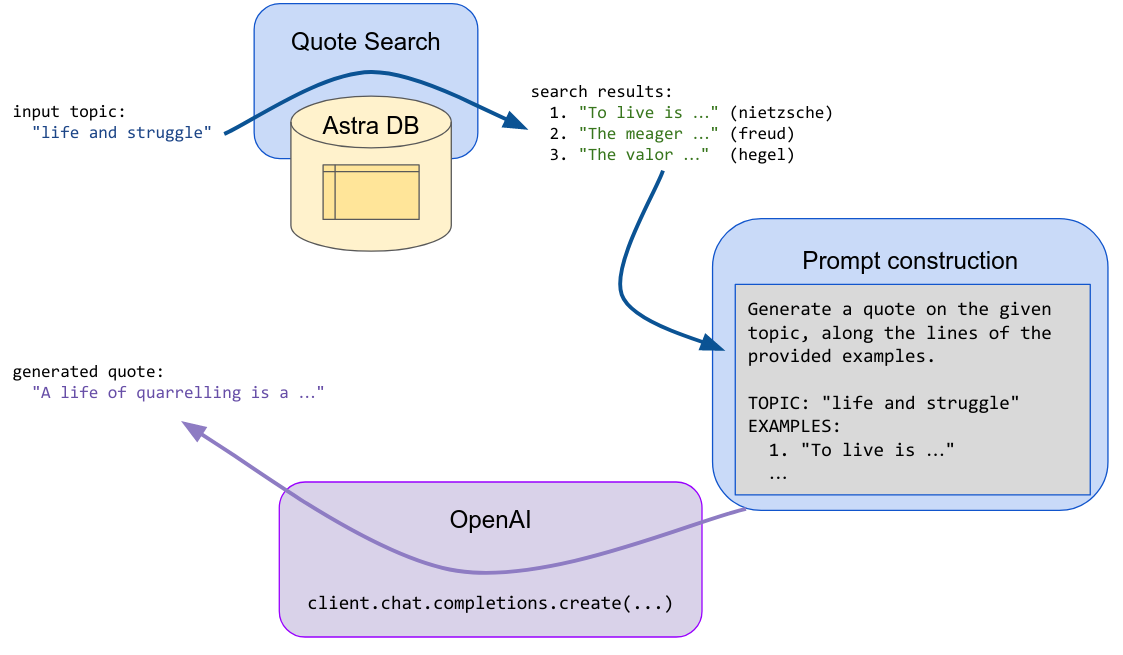
生成
给定一个建议(一个主题或一句试探性的名言),将执行搜索步骤,并将返回的第一个结果(名言)输入到 LLM 提示中,要求生成模型根据传入的示例_和_初始建议来发明新的文本。
设置
安装并导入必要的依赖项:
!pip install --quiet "astrapy>=0.6.0" "openai>=1.0.0" datasets
from getpass import getpass
from collections import Counter
from astrapy.db import AstraDB
import openai
from datasets import load_dataset
连接参数
请在您的 Astra 仪表板上检索您的数据库凭据(信息):您将稍后提供它们。
示例值:
- API 端点:
https://01234567-89ab-cdef-0123-456789abcdef-us-east1.apps.astra.datastax.com - 令牌:
AstraCS:6gBhNmsk135...
ASTRA_DB_API_ENDPOINT = input("请输入您的 API 端点:")
ASTRA_DB_APPLICATION_TOKEN = getpass("请输入您的令牌")
请输入您的 API 端点: https://4f835778-ec78-42b0-9ae3-29e3cf45b596-us-east1.apps.astra.datastax.com
请输入您的令牌 ········
实例化 Astra DB 客户端
astra_db = AstraDB(
api_endpoint=ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
)
创建向量集合
除了集合名称之外,唯一需要指定的是您将存储的向量的维度。其他参数,特别是用于搜索的相似性度量,是可选的。
coll_name = "philosophers_astra_db"
collection = astra_db.create_collection(coll_name, dimension=1536)
连接到 OpenAI
设置您的密钥
OPENAI_API_KEY = getpass("请输入您的 OpenAI API 密钥: ")
请输入您的 OpenAI API 密钥: ········
嵌入的测试调用
快速检查如何获取输入文本列表的嵌入向量:
client = openai.OpenAI(api_key=OPENAI_API_KEY)
embedding_model_name = "text-embedding-3-small"
result = client.embeddings.create(
input=[
"This is a sentence",
"A second sentence"
],
model=embedding_model_name,
)
注意:以上是 OpenAI v1.0+ 的语法。如果使用早期版本,获取嵌入的代码将有所不同。
print(f"len(result.data) = {len(result.data)}")
print(f"result.data[1].embedding = {str(result.data[1].embedding)[:55]}...")
print(f"len(result.data[1].embedding) = {len(result.data[1].embedding)}")
len(result.data) = 2
result.data[1].embedding = [-0.0108176339417696, 0.0013546717818826437, 0.00362232...
len(result.data[1].embedding) = 1536
将名言加载到向量存储中
获取包含名言的数据集。(我们改编并扩充了来自 此 Kaggle 数据集 的数据,已准备好用于此演示。)
philo_dataset = load_dataset("datastax/philosopher-quotes")["train"]
快速检查:
print("一个示例条目:")
print(philo_dataset[16])
一个示例条目:
{'author': 'aristotle', 'quote': 'Love well, be loved and do something of value.', 'tags': 'love;ethics'}
检查数据集大小:
author_count = Counter(entry["author"] for entry in philo_dataset)
print(f"总计: {len(philo_dataset)} 条名言。按作者划分:")
for author, count in author_count.most_common():
print(f" {author:<20}: {count} 条名言")
总计: 450 条名言。按作者划分:
aristotle : 50 条名言
schopenhauer : 50 条名言
spinoza : 50 条名言
hegel : 50 条名言
freud : 50 条名言
nietzsche : 50 条名言
sartre : 50 条名言
plato : 50 条名言
kant : 50 条名言
写入向量集合
您将计算名言的嵌入,并将它们与文本本身以及稍后将使用的元数据一起保存到向量存储中。
为了优化速度并减少调用次数,您将执行批量调用 OpenAI 嵌入服务。
要存储名言对象,您将使用集合的 insert_many 方法(每个批次一次调用)。在准备要插入的文档时,您将选择合适的字段名——但请记住,嵌入向量必须是固定的特殊 $vector 字段。
BATCH_SIZE = 20
num_batches = ((len(philo_dataset) + BATCH_SIZE - 1) // BATCH_SIZE)
quotes_list = philo_dataset["quote"]
authors_list = philo_dataset["author"]
tags_list = philo_dataset["tags"]
print("开始存储条目: ", end="")
for batch_i in range(num_batches):
b_start = batch_i * BATCH_SIZE
b_end = (batch_i + 1) * BATCH_SIZE
# 为此批次计算嵌入向量
b_emb_results = client.embeddings.create(
input=quotes_list[b_start : b_end],
model=embedding_model_name,
)
# 准备要插入的文档
b_docs = []
for entry_idx, emb_result in zip(range(b_start, b_end), b_emb_results.data):
if tags_list[entry_idx]:
tags = {
tag: True
for tag in tags_list[entry_idx].split(";")
}
else:
tags = {}
b_docs.append({
"quote": quotes_list[entry_idx],
"$vector": emb_result.embedding,
"author": authors_list[entry_idx],
"tags": tags,
})
# 写入向量集合
collection.insert_many(b_docs)
print(f"[{len(b_docs)}]", end="")
print("\n已完成存储条目。")
开始存储条目: [20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][10]
已完成存储条目。
用例 1:名言搜索引擎
对于名言搜索功能,您首先需要将输入的引语转换为向量,然后使用它来查询存储(除了处理可选的元数据到搜索调用中)。
将搜索引擎功能封装到一个函数中以便于重用。其核心是集合的 vector_find 方法:
def find_quote_and_author(query_quote, n, author=None, tags=None):
query_vector = client.embeddings.create(
input=[query_quote],
model=embedding_model_name,
).data[0].embedding
filter_clause = {}
if author:
filter_clause["author"] = author
if tags:
filter_clause["tags"] = {}
for tag in tags:
filter_clause["tags"][tag] = True
#
results = collection.vector_find(
query_vector,
limit=n,
filter=filter_clause,
fields=["quote", "author"]
)
return [
(result["quote"], result["author"])
for result in results
]
测试搜索
只传递一句名言:
find_quote_and_author("We struggle all our life for nothing", 3)
[('Life to the great majority is only a constant struggle for mere existence, with the certainty of losing it at last.',
'schopenhauer'),
('We give up leisure in order that we may have leisure, just as we go to war in order that we may have peace.',
'aristotle'),
('Perhaps the gods are kind to us, by making life more disagreeable as we grow older. In the end death seems less intolerable than the manifold burdens we carry',
'freud')]
限制作者的搜索:
find_quote_and_author("We struggle all our life for nothing", 2, author="nietzsche")
[('To live is to suffer, to survive is to find some meaning in the suffering.',
'nietzsche'),
('What makes us heroic?--Confronting simultaneously our supreme suffering and our supreme hope.',
'nietzsche')]
限制为某个标签的搜索(从之前与名言一起保存的标签中):
find_quote_and_author("We struggle all our life for nothing", 2, tags=["politics"])
[('He who seeks equality between unequals seeks an absurdity.', 'spinoza'),
('The people are that part of the state that does not know what it wants.',
'hegel')]
剔除不相关结果
向量相似性搜索通常会返回最接近查询的向量,即使这意味着结果可能有些不相关,如果没有任何更好的结果的话。
为了控制这个问题,您可以获取查询与每个结果之间的实际“相似性”,然后对其设置一个阈值,从而有效地丢弃超出该阈值的结果。 正确调整此阈值并非易事:在这里,我们只向您展示方法。
为了感受它是如何工作的,请尝试以下查询,并调整名言和阈值的选择以比较结果。请注意,相似性作为每个结果文档中的特殊 $similarity 字段返回——并且默认情况下会返回该字段,除非您将 include_similarity = False 传递给搜索方法。
注意(对于有数学倾向的人):此值是对向量之间余弦差(即标量积除以两个向量范数的乘积)的零到一的重新缩放。换句话说,对于相反方向的向量,此值为 0,对于平行向量,此值为 +1。对于其他相似性度量(余弦是默认值),请查看 AstraDB.create_collection 中的 metric 参数以及允许值的文档。
quote = "Animals are our equals."
# quote = "Be good."
# quote = "This teapot is strange."
metric_threshold = 0.92
quote_vector = client.embeddings.create(
input=[quote],
model=embedding_model_name,
).data[0].embedding
results_full = collection.vector_find(
quote_vector,
limit=8,
fields=["quote"]
)
results = [res for res in results_full if res["$similarity"] >= metric_threshold]
print(f"阈值内的 {len(results)} 条名言:")
for idx, result in enumerate(results):
print(f" {idx}. [similarity={result['$similarity']:.3f}] \"{result['quote'][:70]}...\"")
阈值内的 3 条名言:
0. [similarity=0.927] "The assumption that animals are without rights, and the illusion that our treatment of them has no moral significance, is a positively outrageous example of Western crudity and barbarity. Universal compassion is the only guarantee of morality. ..."
1. [similarity=0.922] "Animals are in possession of themselves; their soul is in possession o..."
2. [si
```